
我們越來越接近大一統,接近智能的本質。
作者|甲小姐 劉楊楠
經過1個月的發酵,國內AI從業者們對Sora的態度正發生著微妙的轉變,從最初的震撼,到被未知裹挾的好奇、質疑,再到最近開始隱約出現“復現Sora”的潮流。
1份技術報告,32篇引用論文,一些畫面堪比電影鏡頭的demo和1個故作高深的“世界模擬器”概念就是OpenAI給出的全部,沒有技術論文,也沒有可公開體驗的產品入口。
OpenAI給全世界出了一系列謎題——Sora的技術架構到底是什么?和ChatGPT有什么聯系?訓練Sora是否會燒掉更多資金和算力?開源有機會反超Sora嗎?OpenAI口中的“世界模擬器”到底是什么......?
本次對話的主人公李志飛,便是沖在一線破解謎題的人。
李志飛,出門問問創始人、CEO,美國約翰霍普金斯大學計算機系博士,前Google總部科學家,自然語言處理及人工智能專家,創業10年主導開發過語音助手、智能硬件,以及多個AIGC產品,如魔音工坊、奇妙元。
2022年底,感受到ChatGPT帶來的心智沖擊后,李志飛直接飛到美國,在距離OpenAI最近的地方尋找答案;但今年,李志飛沒跟任何人聊,在他看來,“OpenAI很狡猾,他們試圖隱藏一些東西”,而目前國內外社交媒體上對Sora激情評論的人基本“都是瞎猜”。
“過多的猜測只會浪費時間,既然找不到答案,還不如自己研究。”近一個月,李志飛一門心思研究Sora的原理,他幾乎看遍了OpenAI列出的32篇論文。現在,他已經拼出了一幅完整的Sora技術架構圖。
一年前,幾乎是相同的時間,「甲子光年」曾與李志飛圍繞ChatGPT的“煉丹大會”有過一次對話;一年后,甲小姐再次對話李志飛,主題轉變為“理解Sora,復現Sora”。
1.談感受:“理解是沒有終點的,我們只能無限逼近真相”
“我不覺得他們能有比我更深的認知,都是瞎猜。 既然找不到真正的答案,我還不如自己研究。”
甲小姐:到今天為止,你對Sora理解到什么程度?
李志飛:我基本讀完了所有Sora相關的論文,對Sora的理解更深了。但理解Sora不是封閉的數學題,現在我們對Sora的理解可能邏輯起點都是錯的,是否在某個地方做了隱性假設都不知道。理解是沒有終點的,我們只能無限逼近真相。
甲小姐:Sora跟ChatGPT相比,誰給你的震撼更大?
李志飛:從原理突破來說,肯定是ChatGPT,或者說是它背后的GPT。今天,很多人都看過GPT許多相關論文,但還是很難理解大語言模型為啥有思維鏈(CoT)以及上下文學習(ICL)的能力,這是心智上的沖擊。而Sora真正的沖擊不在原理突破,因為ChatGPT出現后我們都能預見到AI生成高質量視頻是必然的,只是沒料到會這么快。Sora的沖擊是它生成視頻的時長、高質量以及一致性。
甲小姐:Sora在業內引起的反響跟ChatGPT相比,哪個勢能更大?
李志飛:ChatGPT在2022年11月底發布,國內23年1月底才開始大規模討論,2月左右出現創業潮,大概有三四個月的時間大家都非常興奮,覺都睡不著,Sora肯定沒到這種程度。一個重要原因是ChatGPT能直接體驗。Sora的下一次高峰可能是OpenAI開放體驗的時候,現在降火速度非常快。
甲小姐:有人把Sora類比為GPT-3.5時刻,你認同嗎?
李志飛:這完全不對,如果一定要類比,Sora應該是GPT-2到GPT-3的過渡。因為GPT-2跟GPT-3原理上沒什么區別,但GPT-3證明了Scaling law(規模法則)在文本數據上work,Sora進一步證明了Transformer和Scaling law在視頻上同樣能work。
甲小姐:OpenAI沒有把Sora開放給大眾使用,有沒有一種可能是,現在的demo是他們精心篩選的結果,Sora的真實能力遠不及此?
李志飛:有可能。除非Meta的LLaMA-3也立馬搞一個開源模型,能復現類似Sora的效果,以此證明Transformer和Scaling law確實能在視頻生成領域規模化work。
甲小姐:OpenAI可能會在什么時候開放Sora的使用?
李志飛:具體何時不知道,OpenAI的Sora團隊已在最新訪談中明確表示不會很快發布。如果Sora要商業可用,除了解決渲染速度、時間、成本等問題外,版權問題也是一個難點。
文本的版權已經被搜索引擎重塑了一遍。2005-2010年,紐約時報等傳統媒體不斷訴訟谷歌搬運他們的原創內容。經過十幾年的博弈,各方對文字內容版權基本形成共識。視頻還沒有經過這樣的洗牌,大家的版權保護意識非常強。Sora要真正開放使用,可能要面臨比ChatGPT更大的合規問題。
我猜測OpenAI或許已經用了一些電影、電視劇、游戲以及YouTube的數據。如果只用社會媒體的UGC數據,Sora的生成效果可能根本達不到這個質量。
當然,Sora現在只是學術研究的demo,無法證明OpenAI到底有沒有侵權。這也是OpenAI相對于谷歌的優勢——他們在合規方面可以更加“野蠻”。
甲小姐:對于國內公司而言,ChatGPT和Sora哪個追趕難度更大?
李志飛:去年和今年情況不太一樣。去年國內對大語言模型原理的理解不到位,基礎設施也比較差,導致最初的訓練效率很低,GPU的利用率也很低。但好處在于,ChatGPT的原理有公開論文,你只要努力看懂就行。
今天我們在基礎訓練設施方面更成熟,可能只需要去年1/2甚至更少的GPU就能訓練出同樣的模型。但不好的地方是,Sora的技術細節并未公布,比如它用的編解碼器到底是啥?60s的視頻是一次成功生成的還是多次調整prompt的結果?60s是一個token sequence還是拆成了多個15s的token sequences?這些細節決定到底能不能復現。
甲小姐:在你眼中,誰有可能最先做出“中國的Sora”?
李志飛:我不知道。這次我沒跟任何人聊,就是自己看論文,跟我們的工程師討論,甚至連硅谷的人都很少聊。我不覺得他們能有比我們更深的認知,大家都是處于同一起跑線瞎猜。X上面那些人的認知、理解跟我們比也沒有多大差別。去年ChatGPT出現后,我和業內的高頻互動從結果看也對我作用不大。既然找不到真正的答案,我還不如自己研究。
甲小姐:你可以直接找OpenAI的人聊。
李志飛:我懶得找,估計也找不著,OpenAI可能也就10個人做這個項目,再加上保密限制估計也聊不出啥。另外,我們要去實現Sora,并不一定要跟它一模一樣,達到類似的效果就可以,那我肯定要有自己的一套理解去做。
甲小姐:你為什么對Sora有如此大的興趣?
李志飛:一是個人愛好,去年讀了不少多模態的論文,但大部分都是小打小鬧的demo,各說各的,沒啥讓人信服的效果,但Sora的效果讓我特別好奇到底是怎么做到的。二是我認為出門問問過去做的AIGC產品的終局就是視頻生成。比如魔音工坊是為短視頻生成配音,奇妙元是生成數字人視頻。雖然這些產品現在的用戶量和商業化都不錯,但如果Sora這種端到端的技術路線成為主流,我們這些產品沒有跟上就不會有競爭力了,所以我們必須理解并跟上。
2.談原理:“如果我是OpenAI,就做純粹的GPT”
“GPT像人類的‘工筆畫’,一筆一筆地畫,后一筆依賴于前一筆;Diffusion很像人類的‘潑墨畫’,‘一潑即成’,之后在初稿上一遍遍細化,直到最終呈現出一幅高清圖像。”
甲小姐:OpenAI發布的Sora技術報告,你最關注哪個部分?
李志飛:最讓我困惑的是“時空編碼器”,也就是OpenAI怎么把視頻數據轉成patch。
剛開始我一頭霧水,好奇每一步是怎么做的。OpenAI技術報告里也沒怎么寫,我就把編碼器、解碼器相關論文都看了一遍,發現其實沒那么復雜。
這里的patch就是大家常說的token,數據處理的原子性單位。就像人學知識一樣,在一片汪洋大海中,你可能沒有頭緒,不知道怎么學,但把它分成塊,每一塊單獨突破,肯定簡單很多。
甲小姐:概括一下patch的來龍去脈?
李志飛:2021年6月,谷歌推出ViT(Vision Transformer),即用Transformer來做一個圖片分類模型,這篇論文最早提出“patch”的概念,每一個patch可以當作一個token,用Transformer把圖片轉換成tokens。以前做圖片分類不是基于token,都是用CNN提取圖片feature(特征)。
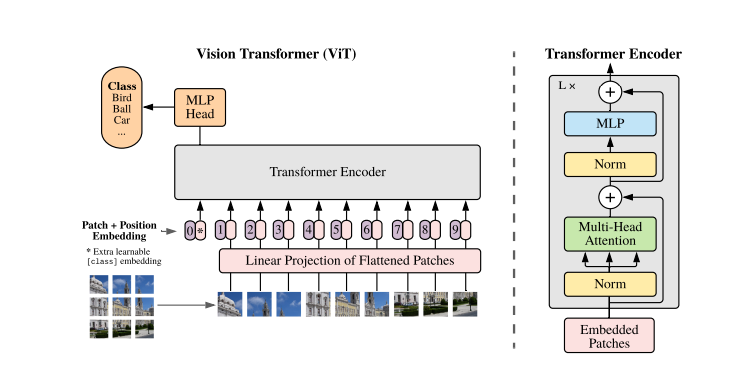
圖片來源:ViT論文
2021年11月,谷歌推出ViViT(Video Vision Transformer,視頻ViT)。把ViT從圖片拓展到視頻,把視頻也轉換成了tokens。視頻增加了時間的維度,這篇論文提出,要從時間和空間的維度同時切塊,即時空patch。
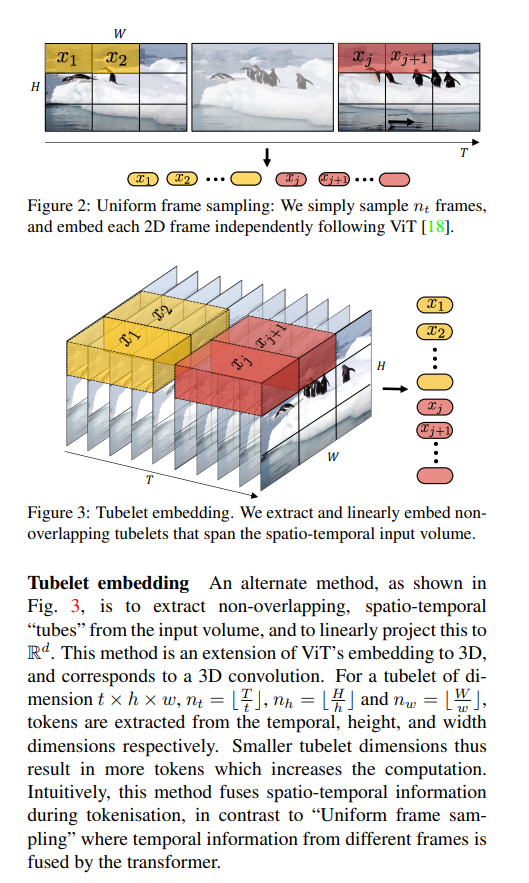
圖片來源:ViViT論文
2023年7月,谷歌提出NaViT(Native Resolution ViT),可以處理不同分辨率、縱橫比的視頻數據。
2023年10月,谷歌又推出MAGViT V2(Masked Generative Video Transformer),解決圖片和視頻聯合訓練的問題。
強調圖片和視頻聯合訓練的原因有二:第一,視頻跟文本對齊的數據很少,但圖片跟文本對齊的數據很多。第二,圖片有很多高分辨率的數據,但視頻沒有。所以圖片跟視頻最好在同一空間、同一vocabulary(詞匯)中聯合訓練。
OpenAI可能還大量使用了模型再生數據。Sora技術報告明確說,他們將所有的訓練視頻與文本對齊,由專門的Dalle-3為之生成相應的captions(說明文字)。
甲小姐:視頻數據token化后,在接下來的處理上和文本有什么本質區別?
李志飛:照常理說,時空切片出來了,相當于視頻數據已經token化,如果用GPT,那一切都簡單了。但大家都猜測OpenAI沒有用GPT,而是用了DiT(Diffusion Transformer)或其變體。
類比來看,GPT的核心架構有三大塊:編碼器(tokenizer)、解碼器(De-Tokenizer)和轉換器(Transformer)。GPT的過程可抽象為:編碼器將數據token化,通過轉換器做上下文依賴關系的建模,再由解碼器轉換為人們熟知的形式。我猜測Sora核心也是這個框架,只是轉換器換成了Diffusion。
甲小姐:到底什么是token?
李志飛:Token是模型處理數據的基本單元,有兩個方面,一是切分成塊,二是分塊后把對應的token值量化。
很多人認為token一定是離散的,這是很大的誤解。Token的值不一定離散,也可以是連續的。對Transformer來說也是如此,只要分塊就可以了,它既可以處理連續值也可以處理離散值的分塊。
文本模型通常使用離散表示,因為文本是天然離散的(文本是由字符或詞構成的字符串),OpenAI用的DiT不需要將token值離散化,模型學的是不同連續值之間的關系。所以他們用的編解碼器引用了VAE(Variational Autoencoder,變分自編碼器),而不是VQ-VAE(Vector Quantization,向量量化)。
Token值的離散和連續關系到模型學習的顆粒度,Tokenize都是為了找到最合適的、最能表示原始數據的學習顆粒度。假設token值的范圍是0-100,如果token量化后以1為單位,就只有101個整數值(vocabulary的大小),但如果token值是連續的,那這個值就有無窮種可能。
甲小姐:從思想上看,GPT和DiT的核心區別是什么?
李志飛:GPT像人類的“工筆畫”,一筆一筆地畫,后一筆依賴于前一筆;Diffusion很像人類的“潑墨畫”,“一潑即成”,之后在初稿上一遍遍細化,直到最終呈現出一幅高清圖像。
甲小姐:既然都可以“畫畫”,為什么不用GPT而用Diffusion?
李志飛:說實話,如果我是OpenAI,就做純粹的GPT,因為GPT擅長捕捉各種依賴關系,包括對長視頻一致性很重要的遠距離依賴關系。
我認為GPT的成功在于next token prediction,模擬人的思考方式。我覺得GPT也能模擬擴散的生成過程。具體來說,GPT生成一版粗糙的token sequence后,把它放在上下文窗口中再次生成下一版更精細的token sequence,如此反復,GPT也能完成擴散模型的“從粗到細”過程,這其實更像人類作畫的方式。
但這對模型的上下文窗口要求很高。比如MAGViT生成2.125秒、幀率為每秒8幀、分辨率為128*128的視頻需要1280個token,生成1分鐘視頻需要3萬多個token;實際場景中分辨率和幀率都會更高,生成一分鐘視頻動不動就要幾十萬的token。
以前不用GPT是因為模型支持處理的上下文窗口不夠長,但這個問題現在已經解決了。如果一切模態的數據都轉成token sequence,用Transformer學習它們之間的關系,那就很通用了。大家的注意力可以放在各種模態的Tokenizer以及數據收集上。
甲小姐:既然如此,為什么過去文生圖一般選擇用Diffusion?
李志飛:我猜測大家選擇Diffusion,一是為了降低模型每一次學習的復雜度,二是為了找到正確的模型學習顆粒度。Diffusion把整個生成過程拆分為很多版本,不斷加噪、降噪,完成從粗到細的過程,從而生成高分辨率的圖片或視頻。
加噪、降噪本質是一種模擬人類作畫的過程。模型難以學會一次性生成最終版圖片,最好有不同清晰度的圖片數據用來訓練模型,比如第一版用粗略的輪廓圖,第二版加入細節線條,第三版加顏色,第四版調整對比度,以此類推。但這些數據很匱乏,于是人為對一張圖片加噪,制造不同清晰度的圖片數據用于模型訓練。降噪的過程則是把文本prompt作為條件,讓模型學習不同版本圖片之間的關系,進而學會把模糊的圖片還原輸出最終的高清圖。
甲小姐:DiT路線會成為文生視頻領域的“大一統范式”嗎?
李志飛:之前文生視頻有不同路線,有的是U-Net,代表包括SD、Gen-2、Pika等;也有把U-Net換成Transformer的,即DiT(Diffusion Transformer),Sora就是這條路。
我認為把U-Net換成Transformer應該是共識。Transformer更加scalable,最終可能會遵循Scaling law;而且,大家花了大量精力和金錢優化Transformer的工具鏈,各種論文也特別多,現在研究U-Net的人少了。
但是否一定要用Diffusion?我認為不一定。我個人覺得用GPT把語言和視覺等模態統一處理更好。
目前還處于技術早期、沒有收斂,各種視頻相關模型的分類或講法比較混亂。我一直說OpenAI“狡猾”,他們的技術報告只是很籠統地引用了幾篇谷歌的文章,但沒說到底用了什么,怎么用的,以及做了哪些創新,感覺OpenAI在隱藏一些東西,你不知道他到底用了什么。
甲小姐:OpenAI的技術報告中強調了模型處理可變時長、分辨率、寬高比數據的能力,這些問題為什么重要?有多難?
李志飛:自然界能收集到的圖像數據有各種格式,比如不同分辨率,不同縱橫比、不同時長。但以前學術研究為了簡單,一般先把各種格式轉換成一個固定格式。這相當于模型還沒開始訓練,在數據處理環節就丟失了很多信息。
處理各種格式并不難,只是在學術界看來都是臟活累活,他們可能不愿意干。但如果要做一款面向公眾的產品,用戶的數據和需求一定是多格式、五花八門的,就必須解決這個問題。
甲小姐:Sora用的很多技術路徑都來自谷歌,你認為OpenAI真正的貢獻是什么?
李志飛:OpenAI真正的原創貢獻是對Scaling law(規模法則)的信仰和實踐。另外,他們把產品目標定義得非常好,比如說,別人都是生成幾秒視頻,他們敢于一開始把目標定為生成一分鐘視頻。如果這個目標實現很好的效果,就能對人產生很大的沖擊;也正因為目標定義足夠清晰,所以他們能夠拆解一系列細分問題,并在文獻中找到答案,而不需要每一個地方都自己做研究。
3.談猜想:“視頻生成的任務復雜度不見得比語言模型更大”
“跨模態的知識遷移超級重要。如果語言模型和視頻模型能夠深度融合,最終可能會實現技術路線的‘大一統’。”
甲小姐:視頻生成的算力需求比文本更高嗎?
李志飛:我也沒有答案。但如果視頻模型一定比語言模型的算力需求還多,那我們就不用努力了,因為已經沒什么意義了。我之所以努力看論文、想復現,是因為我覺得視頻不像大家說的那樣需要比文本多很多倍的算力。
甲小姐:Sora的模型規模多大?
李志飛:大家猜測Sora可能只有30億參數,我也覺得是百億級別的參數,跟語言模型差了幾個數量級。但是,這讓我們很困惑:如果要讓視頻符合物理規律,那模型得有大量的世界知識,但模型又不大,這些知識從哪來呢?
現在大致有兩種方法:一種是將語言模型的知識遷移到下游模態中,讓視頻繼承語言模型里海量的常識,這會大大降低對視頻數據質量和數量的需求,也會大大降低模型學習的難度;另一種是,只拿文本跟視頻的匹配對去訓練,這種匹配對含有的文本量很少,與幾百萬小時的視頻相對齊的文本可能只有幾百億token,跟訓練語言模型的萬億級別文本差距比較大。
甲小姐:Sora是否是跟ChatGPT結合的模型?
李志飛:我們之前分析得出,Sora跟語言模型沒有深度融合,語言模型的世界知識沒有有效遷移過來。如果只靠文本跟視頻對齊的數據來訓練模型,文本數量是非常少的,那么憑什么這個模型能夠很好地學到世界知識,同時生成符合世界知識的視頻?
我有個猜想:當我們用視頻和文本聯合訓練模型,我們就有可能用比純語言模型小很多的文本量,學出很好的世界模型。在這個前提下,視頻生成的任務復雜度不見得比語言模型更大。
我總結一下,一種方式是純文本的模型去學世界知識;另外一種是用文本跟視頻的對齊去聯合學習世界知識。雖然文本數量遠小于以前的全文本數據量,但還有大量視頻tokenize后的tokens,另外視頻模型的參數可能比語言模型小,此消彼長,最后視頻模型和純語言模型的算力需求可能相當。
甲小姐:這個猜想很有意思,有點像小孩子成長的過程,要么死讀書,要么一邊讀書一邊在外面實踐。
李志飛:核心是grounding(抽象概念和實際的聯結)。視頻、圖片是對文本抽象概念的一種grounding,哪怕你在文本里已經知道物理定義,但如果你沒見過圖片或視頻,你腦海里還是沒有特別具象的理解。
甲小姐:OpenAI內部已經開始做知識遷移了嗎?
李志飛:我不知道,真的不知道,我再一次說OpenAI很狡猾。
我認為現在視頻和文本是比較解耦的關系,GPT和Sora可能還是兩個單獨的模型,GPT生成文本的embedding(嵌入)只是作為視頻生成的一個條件,用來指導視頻的生成。
而Google的Gemini和RT-2反而是先把語言模型訓練得很大,基于語言模型再加視頻、圖片和文字的對應關系,再接著往下訓練,這樣文本知識自然就遷移到下游的多模態任務里——這就是我一直強調的跨模態知識遷移。
比如,如果我們生成一只杯子掉在地板上的視頻。今天的大語言模型本身就含有玻璃會碎、水會濺出等常識。如果不繼承這些常識,視頻生成模型還需要大量類似玻璃掉地的視頻數據來訓練。此外,語言模型還包含了對其它物理規律(比如聲光電、碰撞等)的各種描述,這些知識都可以遷移到下游其它模態模型里。
跨模態的知識遷移超級重要。如果我是OpenAI的工程師,我一定會重點做知識遷移。如果語言模型和視頻模型能夠深度融合,最終可能會實現技術路線的“大一統”。
4.談爭議:“大家不能對世界模擬器太認真”
“世界模擬器往深了研究是研究物理,然后你可能會變成研究神學。”
甲小姐:Sora發布后你寫了一篇文章《為什么說Sora是世界的模擬器?》,現在你對世界模擬器有新思考嗎?
李志飛:當時我還沒有系統性看論文,還不知道原理,現在我覺得大家不能對世界模擬器太認真。現在大家對世界模擬器想太多了。世界模擬器往深了研究是研究物理,然后你可能會變成研究神學。(笑)
甲小姐:工程師就是有“造物”情結。
李志飛:如果一直往下思考,你會進入一個很難具象的討論,每個人都有自己的理解。上次有個活動在討論Sora到底是不是世界模擬器,各說各的,沒有一個具象的討論基礎,聽得我都快睡著了。我現在一門心思只想知道Sora到底是怎么做到的,以及我該怎么復現Sora。
甲小姐:如果一定要回答,那你覺得Sora是否學會了世界模型?
李志飛:如果你期望Sora學會了很多物理現象背后精準的數學公式(所謂解析解),比如說F = ma,V_t = V_0 + a*t,那Sora大概率沒有學會世界模型,甚至永遠都沒法靠數據驅動學會。
如果你接受Sora學會很多物理現象展示的輸入和輸出的近似關系(所謂數值解),而且參數的數量遠超精準數學公式里的參數個數,那么Sora大概率學會了世界模型,就算現在還沒有“學會”,很快隨著模型的scale up也能學會。
這就像ChatGPT可能學會了詞性,但它學會的詞性個數和顆粒度跟語言學家定義的可能很不一致。某種程度,我認為ChatGPT的詞性定義可能更合理、更符合語言的規律。
甲小姐:你到底相信哪一種?
李志飛:相信第一種的“沒學會”和第二種的“學會”本質不沖突,就看你是否抱著一種開放的心態,是否接受AI可以有跟人類不一樣的世界觀。如果你自負地認為人類總結的物理規律就是“偉光正”,那當我沒說。
而且,就算Sora學會了世界的數值解,也只是人類觀察到的世界,這個世界是“真”的嗎?是不是模擬出來的?那什么是“真實”世界?你看,我們進入了討論神學的境界。(笑)
甲小姐:大家對世界模擬器的期待或許并不在于它理解所有因果關系,而是好奇沿著暴力美學的路徑,能否實現用AI將整個物理世界數字化,繼而演繹真實世界的可能性,這樣人類可以從中選取最優解。例如工業界能夠降低試錯成本,科學界可以通過暴力美學發現未知的科學現象。
李志飛:我們要定義清楚什么是世界模擬。如果從人的視角看,科學、工業都是人占主導,自然界只是配合,只要是人工的,由于我相信AGI會大概率超越人類,所以我相信AI能模擬和預測世界。如果從上帝視角看,世界還有很多事情是自然占主導,人類只是配角。比如災難、風雨電雷以及各種未知的自然現象,人對這些問題無能為力,這個世界的90%,我們人類可能都沒見過,我們憑什么去模擬它?除非上帝的規則很簡單。
甲小姐:要做世界模擬器要解決幻覺問題,60秒的視頻里面任何一幀違反了力學或者光學定律就會不真實。假設幻覺問題始終解決不了,Sora的應用范圍是不是就被鎖在“文藝工作者”這個角色里了?
李志飛:我認為終局不是兩極分化的。幻覺問題百分之百不能徹底解決的。聯結主義的核心就是“打碎重來”,一定會產生幻覺,這是它的feature,是它的基因。不像符號主義,只組合,不“打碎”,所以不會產生太多幻覺。
ChatGPT和Sora雖然不能生成沒有任何差錯的世界,但并不代表它不能對世界模擬做出很多貢獻。比如自動駕駛,我們可以用Sora生成很多以前根本搞不定的corner case,幫自動駕駛收集數據。
甲小姐:現在我給Sora提出同樣的問題,它給我的答案“可重現”嗎?
李志飛:訓練模型的過程在采樣、加噪、降噪、預測環節都有很多隨機變量,如果要復現一模一樣的視頻,你只能把第一次采樣的隨機變量記下來,重現時不要再隨機產生。但重現本身沒有意義,模型不是這么玩的,你重現這個視頻的生成還不如直接copy原來的視頻。
5.談競爭:“人才密度太高對大公司反而是問題”
“OpenAI一周就搞定的事情,他們可能兩個月都搞不定。”
甲小姐:為什么很多人在谷歌沒有做出ChatGPT、Sora這樣驚艷的產品,到了OpenAI就能做到?
李志飛:OpenAI使用的很多技術是谷歌之前做出來的工作,但很多都是學術論文,不是完整的工程系統,更別說產品了,只是個半吊子。
我之前也很困惑,我每次都覺得谷歌應該能跟得上,至少不會被OpenAI碾壓,但這次在視頻模型上又被OpenAI打得完全找不到牙。很多人把OpenAI的成功歸因于它有很多天才,哪有那么多天才?你看一看谷歌團隊的簡歷,哪個比OpenAI差?
但谷歌內部組織的復雜性和政治正確的文化,讓他們很難做出好的生成式產品。
寫論文或做算法是小規模協作,可能頂多10個人,大家志同道合,就能做出一個原型系統,對組織力要求不高。但如果要面向公眾發布一款生成式AI產品就非常難。生成式AI產品本身就有很大爭議性,比如Deepfake(人工智能深偽技術)等隱患對大眾追求的確定性有很大的沖擊。
谷歌作為公眾公司,從算法原型到產品上線有難以跨越的鴻溝。具體來說,Google的算法團隊Google Research和DeepMind都沒有自己直接掌控的產品。如果要做新產品,谷歌CEO又不強勢,二十多萬人的公司,誰來own視頻生成這類全新產品就成了巨大的難題。產品要上線就更難了,研發、PR、市場、 合規等各部門都有自己的考慮。大公司確實應該考慮這些,但這會讓內部消耗很大。OpenAI一周就搞定的事情,他們可能兩個月都搞不定。
甲小姐:這是否是所有公眾公司都面臨的問題?
李志飛:美國大公司都存在這些問題,谷歌尤其典型。
因為谷歌人才密度太高,同一個研究方向有很多算法研究員和工程師,他們也會相互搶項目。你看過去幾個月谷歌已經發布了好幾個視頻相關的模型,比如Gemini、VideoPoet、Lumiere等。這會讓產品團隊很困惑自己到底該用哪個模型。同一個方向,由于人才太多,他們算法團隊可能有五六個,產品團隊也有五六個,你可以算一下能產生多少交叉組合。
另外,工程師文化很理性,想搶到項目就要證明“我的模型比你好”——這本身就是一件巨復雜、巨耗時間的事情。
我聽說谷歌有團隊去年本來做了視頻生成模型,差不多就要集成到YouTube,但另外一個視頻生成模型的團隊負責人聽到消息,就去和YouTube說應該用他們的模型。產品部門一方面迫于大佬的壓力,另一方面也想看看到底誰更好,就開始評估。大家都說自己好,用自己的數據、benchmark跑一通,誰也說服不了誰,最后只能請外部團隊來評估,又要搞一堆事,幾個月又過去了。
坦白講,很多時候模型之間不會有太大差別,可能我今天比你差一點,我改一改,效果又跟你差不多了,就跟國內to B企業去競標一樣。很多最后都是靠關系或者低價取勝,而不是靠技術。To B項目競標折騰下來要大幾個月,谷歌內部產品可能也類似。到最后大家看產品上線無望,干脆離開,人才可能都被挖走了。
由于谷歌人才密度太高,我一直認為谷歌應該把算法團隊拆成“開源模型、內部產品模型、前沿研究模型”三大塊,各自有所側重——開源更多面向開發者,要做得更通用、更輕量級,有更多工具鏈;內部產品模型團隊則面向用戶,相對to C,主要指標就是用戶體驗;前沿研究團隊可以多花精力研究新算法。在人才等資源充分情況下,分開或許反而使每個項目都有ownership(主人翁意識),也有清晰的方向,不會一片混沌。
6.談應用:“模型應用的最終形態一定是視頻生成”
“很多人老說開源‘套殼’,那都是不懂的人在瞎掰——你為什么要花大量時間、金錢和精力重新造個輪子,還不如別人的好?”
甲小姐:去年你曾說王慧文官宣的動作是想“嚇退”其他人,但今年大家好像都沒有被“嚇退”,反而對復現Sora都很有信心。
李志飛:作為初創公司,更多是從融資方面被“嚇退”。比如說做語言模型,很多人的投入可能是我們的10倍甚至50倍,我們也沒融資。一年下來,我們除了少燒幾個億外,語言模型的認知或實踐也不見得就比同行差。我有種感覺,受限的資源更能做出創新。
甲小姐:對于復現Sora,你已經有信心了嗎?
李志飛:理論上是的,但真正要復現還需要很多細節,可能一個超參數就決定了能否生成高質量視頻。這更多是我們工程師要干的活,他們要做各種實驗,我只是抓住大的方向。
我給內部團隊打氣,說我們是少有的既懂語言模型、又有視頻應用用戶和數據的公司,所以我們有潛力做出好的視頻模型。
但是,從公司投入上看,我們百分之百不可能像OpenAI那樣做,因為我們沒法那樣燒錢,也不想那么做。就像去年2月追趕ChatGPT一樣,我跟人說復現ChatGPT可能有“乞丐版”搞法。后來開源的LLaMA出來后,確實成就了很多“乞丐版”的ChatGPT。
很多人老說開源“套殼”,那都是不懂的人在瞎掰——你為什么要花大量時間、金錢和精力重新造個輪子,還不如別人的好?我覺得核心是弄懂開源背后的細節,能在它基礎上做創新。
甲小姐:誰最可能做出“乞丐版”Sora?
李志飛:如果我是Meta的LLaMA開源團隊,我必須搞。因為即使是做語言模型,要達到所謂的AGI水平,必須要有視頻的模態。某種意義上,能解決視頻的“生成”,“理解”自然就解決了。
甲小姐:為什么生成解決了,理解就解決了?
李志飛:以語言為例,以前文本的理解是專門訓練模型做情感分類、畫語法樹、做詞性分析,都是單獨做理解任務。但ChatGPT基于prompt的接口方式,一個生成模型把所有的理解任務都cover了。從原理上看,我相信只要你能回答出針對性的問題,就算是理解了,就像考試會出很多題目考我們對知識的理解一樣。
甲小姐:我認可生成是證明理解最好的方式。某種意義上,我們對于“理解”的定義本來就很模糊,但“生成”清晰得多。“理解”是內化,“生成”是外化。
李志飛:沒錯。而且,生成是用戶能直接感受到的,更容易商業化。比如,語音識別是理解,很難商業化;但語音生成的商業化就更容易,我們的魔音工坊商業化就比較成功,因為用戶能感知到。
甲小姐:你對要做的產品有定義了嗎?
李志飛:我還沒有考慮到視頻的產品形態那一層,更多是先解決技術疑問。感覺Sora現在還不是產品,它沒有應用場景。我們只是在盡量讓我們的視頻生成模型接近Sora的效果。視頻生成有很多路徑,Sora實現了最徹底的端到端生成,而且很通用。
從產品角度來說,我們做模型的終局就是視頻生成,而且我們更關注短視頻。但以前我也下不了決心,很難想象有一天能夠端到端生成高質量的視頻,但Sora讓我們看到了希望。以前我也看過相關論文,但沒有系統研究過他們之間的關系。Sora的技術報告把32篇論文串聯在一起,我只用努力把這32篇論文理解清楚就有了個大概思路。
7.談終局:“我們正在接近大一統,接近智能的本質”
“從應用角度,視頻是終局,語言不是最重要的,而且光有語言也意義不大。”
甲小姐:2024年有哪些看點?
李志飛:第一,大家什么時候能用上Sora;第二,誰能復現Sora,最好是以開源的形式;第三,谷歌能不能在視頻生成產品層面有不一樣的表現。對谷歌我現在比較悲觀,覺得他們可能又會發個論文,說可以生成5分鐘的長視頻,在一些榜單上比Sora表現得更好,但可能就是沒有一個真正能打的產品。
甲小姐:國內已經有團隊說自己復現了Sora。
李志飛:這種挺沒意思的,有篇文章寫清華一個團隊說他們做的比DiT早。首先我根本不在意DiT,難點根本不在于把U-Net換成Transformer,而在于怎么在工程上真正做到scale up,提升生成質量,以及怎么從圖片拓展到視頻的時空建模。
從實驗的角度來說, DiT的數據規模很小,國內好像對DiT比較在意,網上都在說DiT,很少有人仔細分析Sora的內部原理。我認為DiT沒那么重要。從復現角度來說,它可能是最容易理解、也最容易被復現的部分。
甲小姐:每一位AI從業者此時可能都站在一個十字路口,下一步是去做文生視頻、具身智能、Agent還是其他……爆點層出不窮,哪條道路是“主路”,你有建議嗎?
李志飛:不同角度肯定有不一樣的思考。我永遠都是用最簡單的“技術-產品-商業化”三個層面思考。我認為從產品和應用角度來看,視頻是終局,語言模型不是最重要的,或者說光有語言是遠遠不夠的。
甲小姐:有人認為“語言就是一切”,LLM以文本的單模態就能實現AGI。
李志飛:從純技術角度我認同語言模型的重要性,語言是認知,圖片、視覺、動作是感知,認知模型最難,機器學會了認知,再學感知就容易多了。但AI很大的價值就是代替人類的繁瑣工作,而社會上絕大多數人不靠語言代表的認知賺錢,而是靠感知。你不能說環衛工人主要是靠認知賺錢,認知是這個工種的基礎,但能賺錢的還是“掃地”這個感知的技能。
所以,語言代表的認知是基礎和起點,聲音、圖片、視頻、動作代表的感知才是應用的閉環。從最終的產品形態來看,只有語言認知意義不大。
對模型層來說,確實要想視頻怎么做,和語言模型有什么關系;對產品端來說,以前視頻生成更多基于模板,現在Sora實現端到端生成,以前的產品也許就會被淘汰——原來的技術路線不升級,產品就沒有競爭力,可能就是“死路一條”。這也是我為啥這么關心Sora的原因之一,我擔心我們現有產品會死。當然,淘汰的過程不會太快,還有成本、版權等問題。Sora完全淘汰上一代視頻生成產品,可能至少還要一兩年。
甲小姐:2024年還會是OpenAI一家獨大嗎?
李志飛:我沒法直接給你答案,還得看Sora開放體驗后,產品能否真正達到demo的效果。如果Sora的demo就是真正的產品能力,那我真的不知道谷歌什么時候能跟上,肯定比追ChatGPT更難。
甲小姐:目前你已經拼出完整的Sora原理版圖了嗎?
李志飛:我的結論只是基于論文,其實真正理解Sora的是一線工程師,因為我沒有看源代碼。最終的本質是代碼,就像要理解這個世界就得拿到上帝的源代碼。如果工程師除了看源代碼外還具備抽象思維,比如想清數據和算法代碼之間的關系,他們就是最理解Sora原理的人。但很多一線工程師對抽象問題沒興趣,更多是拿著別人的東西改代碼,不愿真正理解背后的思想。
甲小姐:OpenAI內部做AGI也會有團隊分工,有點像盲人摸象,每人做一塊,很難有人真正上升維度在抽象意義層面思考全局。
李志飛:以前這個人是Ilya(Ilya Sutskever,OpenAI 聯合創始人兼首席科學家),現在他可能被邊緣化了。
甲小姐:現在AGI真正的源代碼或許還分散在各位一線工程師的腦子里?如果有一位產品經理從上帝視角抽象出整個原理版圖,現在我們對AI的理解或許會更深刻。
李志飛:很多時候工程師沒精力思考抽象問題,他們忙于調參數搞數據。但你要相信,和10年前相比,我們已經越來越接近智能的真相了。以前視覺、圖片、聲音、語言,都是完全不同工種的人通過不同方式在做,現在我們越來越接近大一統,接近智能的本質。

 作者:劉楊楠
2024-03-11
作者:劉楊楠
2024-03-11

 16099
16099 0
0 0
0 0
0
